Project: Project: Segmentation of Gliomas from brain MRI
Overview
Gliomas are Brain tumors that involve glial cells in the brain or spinal cord. Gliomas are classified as grades I to IV, where the grades indicate severity. The grades include grade 1 (benign, curable with complete surgical resection), grade II (low grade, undergo surgical resection, radiotherapy/chemotherapy, grade III/IV (high-grade glioma’s), and grade IV (glioblastoma). The task is to identify the location of the tumor, and its classification into three groups; edema (indicates inflammation), enhancing (indicates part of the tumor with active growth), and the necrotic core (dead tissue, generally in the center). This task is important in practice, as the results are used for surgical planning.
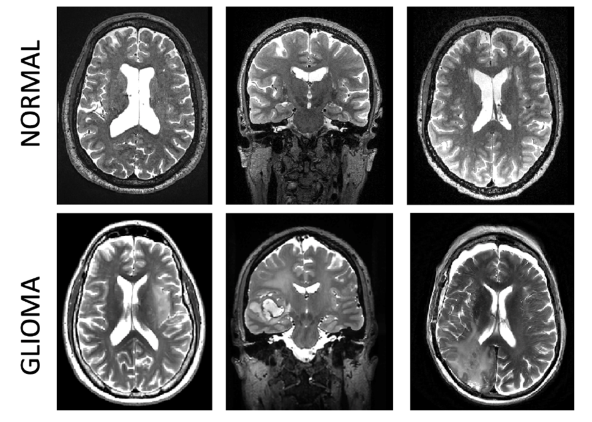
Fig 1 Example 2D slice(s) of the 3D brain image showing both a normal subject (top) and a subject with glioma (bottom).
Four (4) different magnetic resonance images (MRI), also known as contrasts are provided for each subject, T1-weighted (this tends to be higher intensity with tissues with more lipids), T2-weighted (usually higher intensity for tissues with more water), FLAIR (similar to T2 but free water is suppressed), and T1CE (same as T1, but with a contrast agent injected to brighten certain patterns).
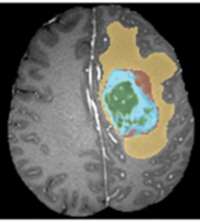
Fig 2 Example 2D slice of the 3D brain image showing a typical pattern of tissue grade.
Project Description
Each sample is a tensor of size = 4 x height (H) x width (W) x depth (D), where the four 3D tensors represent the a) native (T1) and b) post-contrast T1-weighted (T1Gd), c) T2-weighted (T2), and d) T2-FLAIR contrasts (images) of the brain MRI. Note that different samples may have slightly different dimensions H, W, and D -- your are models should be able to handle this. For training samples, you are also provided with a HxWxD label “image”, with a label for each voxel (3D pixel). Your task is to predict the segmentation of unlabelled images. This is also known as semantic segmentation in computer vision. Beyond the course notes, you can find some straightforward descriptions here, and here Note that the output dimension for each sample is of size H x W x D.
Learning Goals
- Gain real-world experience with ML, subject to blind test evaluation
- Investigate the effect of spatially correlated features. The use of convolution and other image processing techniques may be helpful.
- Apply ML with high dimensional inputs and outputs
- Grapple with data preprocessing/cleaning, if necessary
Data
The train and validation split of the dataset are provided on box. You are provided with 204 labeled (training) samples and 68 unlabelled (validation) images, all saved as NumPy tensors (.npy). Download data here (~3GB):
Kaggle Competition and Grading
Your performance will be evaluated via a Kaggle competition. You may sign up for the Kaggle competition here
We will identify you using your NetID. An account created using your NetID is preferable for easy matching during the grading time; however, you may use your existing Kaggle account. Please make sure to fill out the signup form below which includes username details.
You will be restricted to a maximum of 4 submissions per day. The leaderboard shows scores on the validation set. Final grades are based on scores evaluated on a hidden test set with similar distributions as the training and the validation set.
You may work individually, or in teams with a maximum size of 2 Both team members will get the same grade. You can set up teams directly on Kaggle.
Grading: Your project grade will be determined by thresholds, i.e., you achieve a given grade when your performance is better than the appropriate threshold on the hidden test set. Thresholds will be announced before the project competition. Selected grade thresholds will roughly depend on class performance and our internal baseline tests.
Due date: Competition Ends Dec 19, 11:59pm
Prediction:
Test labels are submitted as a csv file to the Kaggle site. Please use utils.py (in the same folder) to convert your predictions into the required format for kaggle submission. Please do not renumber or re-order the samples for kaggle submission.
Evaluation Metric:
The evaluation metric we will be using is the DICE score for each label (also known as intersection over union).
Kaggle username declaration and computation signup form [NOTE: FORM CLOSES DEC 9]. Please sign up for computation (if desired) in this form as well: https://forms.gle/VUXZvYrEw2SbopJB8
Computational Resources
You are free to use any compute resources you like. Microsoft Azure has graciously donated cloud computing credits for each student to use. If you choose to use these, please see the instructions below.
Another great source of compute for the project is Google Colab. It is free to use and gives you access to a Telsa K80 GPU. Set up for this is a bit easier than Azure but in order to run your code you must be in a Colab notebook (same as a Jupyter notebook).
After filling up the Google form (informing us you will use Azure), please signup for a free trial of azure: https://azure.microsoft.com/en-us/free/ using your Illinois email. We will add you to the course compute group to access additional computing resources.
Epilogue
After the competition ends, you will be required to submit (a) an archived version of your code (e.g. zip), and (b) a short (2 sentences) description of your approach. Please submit these by email to student.8h5d3jsobufq7kbi@u.box.com in format [netid1]-[netid2 (optional)]-project.zip.